#정규식(정규표현식) **테스트 사이트: https://regexr.com/
re 모듈 사용함(regular expression)
■문자일치
- 메타문자(정규표현식에서 사용하는 기호) => . ^ $ * + ? { } [ ] \ | ( ) 사용
- [ ] : 문자 하나를 비교함.
- [abc] 이면 a or b or c 문자와 일치하는지 확인함.(하나라도 있으면 True)
~[abc] : 내가 입력한 문자열에서 a가 있는지 -> b가 있는지 -> c가 있는지
- [(abc)] 이면 abc와 일치하는지 확인함.(연달아 하나로 있어야 True)
- [abc]는 [a-c] 처럼 - 를 사용하여 범위를 사용 가능함.(하나라도 있으면 True)
- [ ] 안에서 ^는 포함하지 않는것을 의미함.
- [^a] 는 a를 제외한 모든 문자와 일치함의 의미함.
- [a^] 는 a or ^ 와 일치하는지를 의미함(순서주의)
- \w는 모든 영문자숫자를 의미함 [a-zA-Z0-9] 와 동일함. (특수문자만 빼고)
- \W는 모든 영문자숫자가 아닌 것을 의미함. [^a-zA-Z0-9]와 동일함.
- \d는 모든 십진숫자를 의미함 [0-9]와 동일함.
- \D는 모든 숫자가 아닌 문자를 의미함 [^0-9]와 동일함.
- . 은 개행문자(줄바꿈 문자)를 제외한 모든 문자를 의미함.
- |(파이프) : or 의미, Crow|Servo 는 Crow or Servo 일치함.
~ | 문자자체를 일치하려면 \| 또는 [|] 를 사용함.
- ^ : [ ] 안에서가 아닌 ^의 의미는 줄의 시작 부분의 일치를 의미함
~ ^From 에서 From Korea 는 일치하지만, I am From Korea는 일치하지않음
- $ : 줄의 끝부분과 일치하는지 확인함.
~ }$ 에서 {block} 는 일치하지만, {block}; 는 일치하지 않음
■ 반복하기
- * : 0번 이상 일치하는지 확인함.
~ca*t 는 a문자가 0번 이상인지 확인함. ct, cat, caaat ... : True
- + : 1번 이상 일치하는지 확인함.
~ca+t 는 a문자가 1번 이상인지 확인함. cat, caaat ... : True
- ? : 1번이나 0번과 일치하는지 확인함.(있는지 없는지 확인)
~home-?brew는 homebrew와 home-brew와 일치함.
- {m, n} : 최소 m번 반복, 최대 n번 반복을 확인함.
~a/{1,3}b 는 a/b, a//b, a///b와 일치함.
~{0, } 는 *와 동일함.
~{1, } 는 +와 동일함.
~{0,1} 는 ?와 동일함.
'''
========================================================================================
'''
■정규식 메서드
- ★match() : 문자열의 시작 부분에서 re가 일치하는 판단함.(일치하는 것이 없으면 None 반환함.)
- ★search() : re가 일치하는 위치를 찾으면서 문자열을 읽음.
- ★findall() : re가 일치하는 모든 부분의 문자열을 찾아 list로 반환함.
- finditer() : re가 일치하는 모든 부분의 문자열을 찾아 iter 로 반환함.
'''
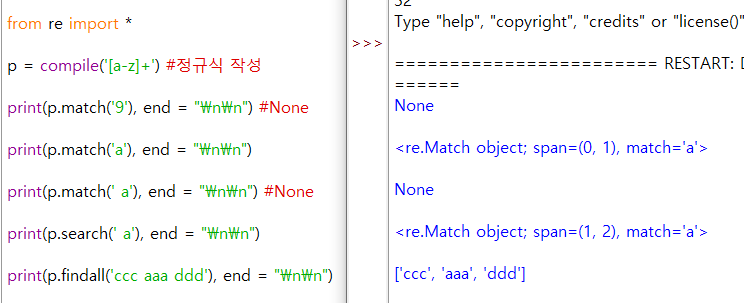
from re import *
p = compile('[a-z]+') #정규식 작성
print(p.match('9'), end = "\n\n") #None
print(p.match('a'), end = "\n\n")
print(p.match(' a'), end = "\n\n") #None
print(p.search(' a'), end = "\n\n")
print(p.findall('ccc aaa ddd'), end = "\n\n")
========================================================================================

from re import *
#주민번호 : [0-9]{6,6}-[0-9]{7,7}
#주민번호 : [0-9]{6}-[0-9]{7}
#주민번호 : \d{6}-\d{7}
p = compile('[0-9]{6}-[0-9]{7}$')
print(p.match('123456-1234567'))
print(p.match('1234561234567'))
print(p.match('1234566-1234567'))
print(p.match('1o23456-1234567'))
print(p.match('123456-12345678899'))
print("\n\n\n\n\n\n")
#핸드폰번호 정규식
p2 = compile('^010-\d{4}-\d{4}$')
print(p2.match('010-1234-5678'))
print(p2.match('010-123-5678'))
print(p2.match('010-1a34-5678'))
print(p2.match('010-12234-5678'))
print(p2.match('010-1234-56788'))
print("\n\n\n\n\n\n")
#아이피 정규표현식 (최소 1~최대3)
p3 = compile('^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$')
print(p3.match('123.456.7.8'))
print(p3.match('123.456.7.89999'))
print("\n\n\n\n\n\n")
# 이메일 정규표현식(아이디 @ 회사 . )
p4 = compile('^[a-zA-Z0-9-_.]+@\w+\.\w+([.]\w+)*$')
print(p4.match('aa12@naver.com'))
print(p4.match('aaa_123@cnu.co.kr'))
print(p4.match('aaa@gmail.com'))
========================================================================================
주민번호와 휴대폰 모두 뒷자리 자리수가 더 많을 때 None이어야 하는데 값을 찾아버리는 불상사가 발생..
ex) 123456-12345678 / 010-1234-56788 일 때 None이 아니라 뒷자리에서 입력한 값만큼 알아서 끊어서 찾아 버렸다.
이에 대해 아무도 이의를 제기하지 않아서 쉬는시간에 조심스럽게 여쭤보았다.
그때부터 강사님의 고뇌 시작...(처음에는 내가 무언가 실수했다고 생각하셨다..ㅠ 아닌데..)
어쨌든 그 고뇌의 결과로 끝에 $를 붙여야 한다는 것을 알게 되었다~
+ 시작할 땐 ^
이메일 정규식 만들 때는 특수기호 중에 포함되는 것이 있는 것, .이 2번 올 수도 있다는 것을 고려하는 게 핵심.
나는 둘다 놓쳤다..^^ 대신 \w에 underscore(_)은 포함된다는 걸 알 수 있었다~~
'파이썬(PYTHON) > 개념정리' 카테고리의 다른 글
| [파이썬(Python)] 크롤링 (0) | 2022.07.31 |
|---|---|
| [파이썬(Python)] 간단한 Quiz (0) | 2022.07.30 |
| [파이썬(Python)] SQL (0) | 2022.07.28 |
| [파이썬(Python)] 클래스 (0) | 2022.07.23 |
| [파이썬(Python)] 디렉토리, 예외 처리 (0) | 2022.07.17 |



