//SELECT문
- DML, DQL
- 관계대수 연산 중 셀렉션 작업을 구현한 명령어
- 대상 테이블로부터 원하는 행을 추출하는 작업 > 오라클 서버에 데이터를 요청하는 명령어
- 읽기(조회)
- 여러 개의 절로 구성됨(★★★★★★★★★★절의 실행 순서는 정해져 있음.) > 각 절의 역할과 순서를 잘 알아둬야 함.★★★
[WITH <Sub Query>] > with절
5. SELECT column_list > select절
1. FROM table_name > from절
2. [WHERE search_condition] > where절
3. [GROUP BY group_by_expression] > group by절
4. [HAVING search_condition] > having절
6. [ORDER BY order_expression [ASC|DESC]] > order by절
//컬럼 조회
select 컬럼리스트 > 2. 원하는 컬럼을 지정
from 테이블명; > 1. 데이터소스를 지정(어느 테이블로부터 데이터를 가져올 것인지 지정)
- 단일 컬럼 조회
~ select first_name from employees;
- 다중 컬럼 조회
1.
select first_name, last_name, email, salary, phone_number from employees;
2.
select first_name, last_name, email, salary, phone_number
from employees;
3.
select
first_name, last_name, email, salary, phone_number
from
employees;
4.
select first_name, last_name, email, salary, phone_number
from employees;
- * : 와일드 카드 > 모든 컬럼 --가독성, 성능면에서는 컬럼명을 모두 명시하는 것이 더 좋음.
- select절의 컬럼 리스트의 컬럼 순서는 원본 테이블의 컬럼 순서와 무관하다.
- 같은 컬럼을 반복해서 가져오는 것도 가능하다.(하지만 그럴 일은 없음)
select first_name, first_name from employees;
※ 가공해서는 사용함!
select first_name, length(first_name) from employees;
- select문의 결과는 항상 테이블이다. > 결과 테이블 > 메모리에 존재하는 임시 테이블
// where절
- 레코드를 검색한다.
- 원하는 행만 추출하는 역할 > 결과셋 반환
select 컬럼리스트 3.원하는 컬럼 지정
from 테이블 1. 테이블 지정
where 조건 2. 조건 지정//DISTINCT : 중복 값 제거
- 컬럼리스트 앞에 distinct를 붙이면 중복된 값은 하나로 검색된다.
- select의 컬럼 리스트에서 사용
- 컬럼이 아닌 레코드를 대상으로 함. > 컬럼이 많아질 수록 중복될 확률이 낮음
- 중복값 제거

SELECT DISTINCT AGE FROM MEMBER;//Case
- 대부분의 절에서 사용
- 조건문 역할 > 컬럼값 조작
case
when 조건 then 반환값
end as 이름 지정
--java의 if문과 비슷
case
when 조건1 then 반환값1
when 조건2 then 반환값2
else 반환값3
end as 이름 지정
--java의 switch-case문과 비슷
case 컬럼명
when 값1 then 반환값1
when 값2 then 반환값2
else 반환값3
end as 이름 지정
select
last || first as name,
gender,
case
when gender = 'm' then '남자'
when gender = 'f' then '여자'
end as genderName
from tblComedian;
select
name,
continent,
case
when continent = 'AS' then '아시아'
when continent = 'EU' then '유럽'
when continent = 'AF' then '아프리카'
else '기타'
end as continentName
from tblCountry;
select
name,
continent,
case continent
when 'AS' then '아시아'
when 'EU' then '유럽'
when 'AF' then '아프리카'
end as continentName
from tblCountry;
select
last || first as name,
weight,
case
when weight > 90 then '과체중'
when weight >= 50 then '정상체중'
else '저체중'
end as state,
case
when weight >= 50 and weight <= 90 then '정상체중'
else '이상체중'
end as state2,
case
when weight between 50 and 90 then '정상체중'
else '이상체중'
end as state3
from tblComedian;
select
name, jikwi
from tblInsa
where case
when jikwi = '부장' then 1
when jikwi = '과장' then 2
when jikwi = '대리' then 3
when jikwi = '사원' then 4
end = 1;//order by
order by 정렬컬럼 [asc|desc]
order by 정렬컬럼 [asc|desc], 정렬컬럼 [asc|desc], 정렬컬럼 [asc|desc] ...... > 다중 정렬
- 결과셋의 정렬
- 원본 테이블의 정렬을 사용자가 관여할 수 없음! > 사용자는 select에서만..
- null값도 정렬되므로 null을 제외하려면 where 절에 is not null을 함께 사용해야 함.
select 컬럼리스트 --3. 원하는 컬럼 지정
from 테이블 --1. 테이블 지정
where 조건 --2. 원하는 행 지정
order by 정렬기준; --1. 순서대로- 이름을 기준으로 역순으로 정렬해서 조회

SELECT * FROM MEMBER ORDER BY NAME DESC;- 회원 중에서 '박'씨 성을 가진 회원 조회(단 나이를 오름차순으로 정렬)

SELECT * FROM MEMBER WHERE NAME LIKE '박%' ORDER BY AGE;- 회원 중에서 '박'씨 성을 가진 회원 조회(단 나이를 오름차순으로 정렬, 나이가 같을 경우 이름 오름차순으로 정렬)

SELECT * FROM MEMBER WHERE NAME LIKE '박%' ORDER BY AGE, NAME;- 직위순으로 정렬 : 부장 > 과장 > 대리 > 사원

select name, jikwi,
case
when jikwi = '부장' then 1
when jikwi = '과장' then 2
when jikwi = '대리' then 3
when jikwi = '사원' then 4
end jikwiSeq
from tblInsa
order by jikwiSeq;
select name, jikwi,
case
when jikwi = '부장' then 1
when jikwi = '과장' then 2
when jikwi = '대리' then 3
when jikwi = '사원' then 4
end
from tblInsa
order by 3;- 직위순으로 정렬 : 부장 > 과장 > 대리 > 사원 (but 숫자 출력 xx)

select
name, jikwi
from tblInsa
order by case
when jikwi = '부장' then 1
when jikwi = '과장' then 2
when jikwi = '대리' then 3
when jikwi = '사원' then 4
end;
select *
from tblInsa
order by case
when ssn like '%-1%' then '1'
when ssn like '%-2%' then '2'
end asc;// group by
- 레코드를 대상으로 그룹을 나누는 역할
- 특정 컬럼을 대상으로 같은 값을 가지는 레코드들끼리 그룹을 묶는 역할
- 각각의 나눠진 그룹을 대상으로 집계 함수를 적용하기 위해서 그룹을 나눔.★★★★★★★★★★
select 컬럼리스트--4. 컬럼을 선택하고
from 테이블 --1. 테이블로부터
where 조건 --2. 원하는 레코드를
group by 기준 --3. 그룹을 나눠서
order by 정렬; --5. 정렬한다.
- group by를 사용할 때 컬럼리스트 제약
1. 집계 함수
2. group by 기준이 된 컬럼

select
buseo,
round(avg(basicpay)) as "평균급여"
from tblInsa
group by buseo;
select
gender,
count(*)
from tblComedian
group by gender;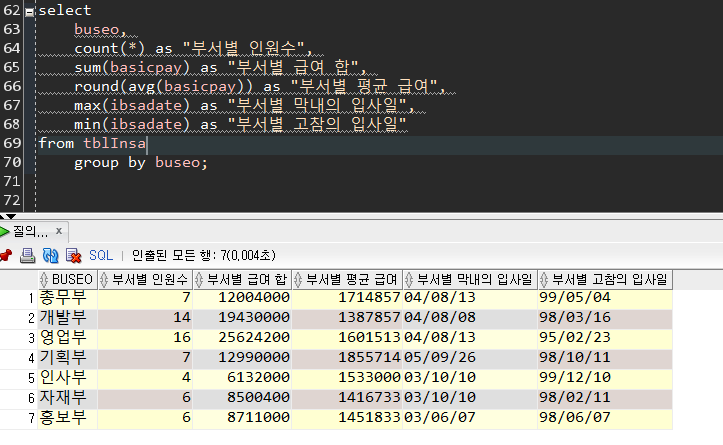
select
buseo,
count(*) as "부서별 인원수",
sum(basicpay) as "부서별 급여 합",
round(avg(basicpay)) as "부서별 평균 급여",
max(ibsadate) as "부서별 막내의 입사일",
min(ibsadate) as "부서별 고참의 입사일"
from tblInsa
group by buseo;
select
job,
count(*)
from tblAddressBook
group by job
order by count(*) desc; --원래는 order by에 집계함수를 쓸 수 없지만, group by에 의해 집계 함수가 컬럼이 되어서 사용 가능- 다중그룹

select
buseo as "부서명",
jikwi as "직위명",
count(*) as "인원수"
from tblInsa
group by buseo, jikwi
order by buseo, jikwi;
select
substr(address, 1, instr(address, ' ') - 1) as "지역",
count(*)
from tblAddressBook
group by substr(address, 1, instr(address, ' ') - 1);
select
substr(email, instr(email, '@')+1) as "도메인",
count(*)
from tblAddressBook
group by substr(email, instr(email, '@')+1)
order by count(*) desc;- group by 함수
1. rollup()
- group by 결과에서 집계 결과를 더 자세하게 반환
- group별 총계(다중그룹수만큼), 모든 group에 대한 총계 반환 (해당 그룹의 결과가 끝날 때마다 밑에..)
- 1차 결산 / 1+2차 결산 / 1+2+3차 결산 ...
- 값을 정렬하여 반환함
2. cube()
- group by 결과에서 집계 결과를 더 자세하게 반환
- rollup()보다 조금 더 자세하게 표현
- 1차 결산 / 1+2차 결산 / 1+2+3차 결산 / 2차 결산 / 3차 결산 ...
- rollup()
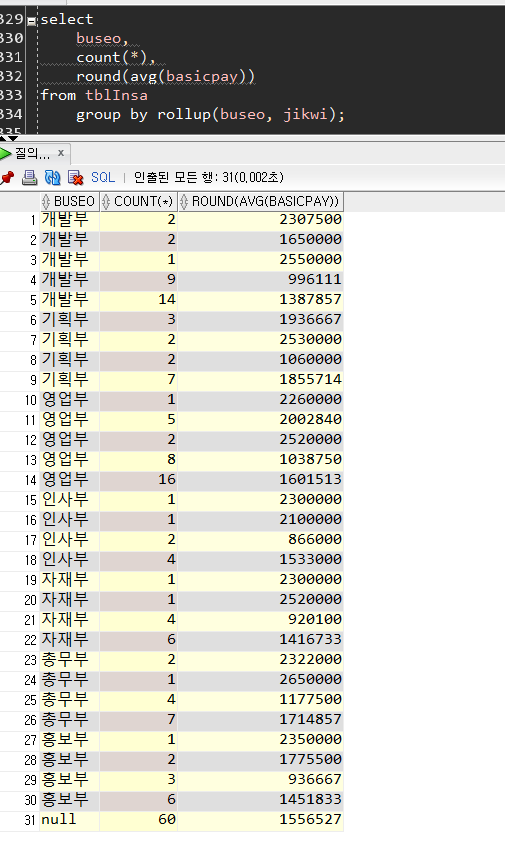
select
buseo,
count(*),
round(avg(basicpay))
from tblInsa
group by rollup(buseo, jikwi);
select
buseo,
count(*),
round(avg(basicpay))
from tblInsa
group by cube(buseo, jikwi);// having
- group by에 대한 조건절
- 집합에 대한 질문 > 집계 함수값을 조건으로 사용
select 컬럼리스트--5. 컬럼을 선택하고
from 테이블 --1. 테이블로부터
where 조건 --2. 원하는 레코드를
group by 기준 --3. 그룹을 나눠서
having 조건 --4. 그룹에 대한 조건
order by 정렬; --6. 정렬한다.
select
buseo,
round(avg(basicpay)) --4. 필터링된 그룹별 집계함수를 각각 구한다.
from tblInsa --1. 60명의 데이터를 가져온다.
group by buseo --2. 60명을 대상으로 > 부서로 그룹을 나눈다.
having avg(basicpay) >= 1500000;--3. 그룹별 집계함수값을 조건으로 필터링
select
count(case
when breath = 'lung' then 1
end) as "변온, 폐 호흡",
count(case
when breath = 'gill' then 1
end) as "변온, 아가미 호흡"
from tblzoo
group by thermo
having thermo = 'variable';

select
email,
count(*)
from tblAddressBook
group by email
having count(email) > 1;※where절 vs having절★★★★★
1. where절
- 개인에 대한 질문(행) > 컬럼값을 조건으로 사용
- from으로부터 나온 set에 대한 조건(실행 순서 : from > where)
2. having절
- group by로부터 나온 set에 대한 조건(실행 순서 : group by > having)
- 집합에 대한 질문 > 집계 함수값을 조건으로 사용
// with절
- 인라인뷰(from절에 사용되는 서브쿼리)에 이름을 붙이는 기술
with 임시테이블명 as (
select
)
- 실행 방식
1. Materialize 방식 > 임시 테이블이 2번 이상 사용되면 내부에 임시 테이블 생성 + 반복 재사용
2. Inline 방식 > 임시 테이블 생성없이 매번 인라인 쿼리를 반복 실행

with seoul as (select name, buseo, jikwi from tblInsa where city = '서울')
select * from seoul;
with a as (select name, age, couple from tblMen where weight < 90),
b as (select name, age from tblWomen where weight > 60)
select a.*, b.age from a inner join b on a.couple = b.name;
with insa as (
select
name, buseo, basicpay,
rank() over(order by basicpay desc) as rnum
from tblInsa
)
select * from insa where rnum = 5;'데이터베이스(DB) > Oracle' 카테고리의 다른 글
| [Oracle] 숫자 함수 (0) | 2023.02.17 |
|---|---|
| [Oracle] 문자열 함수 (0) | 2023.02.16 |
| [Oracle] 정규식 (0) | 2023.02.13 |
| [Oracle] 연산자 (0) | 2023.02.13 |
| [Oracle] 트랜잭션 처리 (0) | 2023.02.11 |



